Local LLM vs Cloud LLM Data Security: The Wrong Question (2026)
The mainstream answer to AI data security is to run a local LLM. For most firms it solves the wrong problem at the wrong cost. The real exfiltration channel is shadow paste on personal ChatGPT accounts — and the right control is sanctioned cloud with data classification and DLP.

Helena Brakespeare signed off £160,000 on a local-LLM proof of concept to keep client data out of the cloud. Six months in, the 8x A100 server in the back office was capped at three concurrent users, its OCR pipeline had broken on scanned medical reports, and nobody had patched the model since install. Then the DLP audit landed. Seven of her nine claims handlers were still pasting redacted-but-not-really policy schedules into personal ChatGPT accounts at lunchtime. The box in the back office had prevented zero of it. The leak was never in the server room. It was in the browser tab.
Quick Answer. For most firms, local LLM vs cloud LLM is the wrong question — a local model solves the wrong problem at the wrong cost. The dominant exfiltration channel is "shadow paste": staff pasting confidential data into personal ChatGPT, Claude or Gemini accounts, outside any corporate tenant or audit log, which an on-prem box does nothing to stop. The right control is a sanctioned cloud LLM under a data-processing agreement with EU/UK residency, plus data classification and endpoint DLP. On-prem stays justified only in narrow cases — classified, air-gapped or statutorily sovereign workloads.
The leak was never in the server room
Shadow paste is the modern data-leak primitive: an employee opens a personal ChatGPT or Claude tab on a phone or home laptop, pastes confidential client material into the prompt to save twenty minutes on a draft, and walks away. The data now sits in a consumer account that, on the default free or Plus tier, may feed the next model's training run. The ICO is explicit that UK GDPR obligations apply "regardless of whether this is incidental or unintentional" [1]. The NCSC asks every organisation to integrate input-side controls "from inception" and to question its supply chain rather than trust it by default [2]. None of those obligations care where the inference server lives. They care which identities can touch which data with which controls. A local model in the server room is irrelevant to a handler with a personal phone and a deadline.
What the DLP audit actually found
At Linthwaite Specialty Brokers, the DLP audit told a clear story. Seven of nine claims handlers were accessing personal ChatGPT or Claude accounts on their phones during the working day. Policy schedules, broker correspondence notes and occasional medical underwriting summaries were moving into free-tier consumer accounts under consumer terms. Not one of those incidents touched the on-prem model. The on-prem model had no reach over personal devices and personal accounts.
Why the SERP cannot see this risk
Every top-ranked article in the "local LLM vs cloud LLM data security" search results frames risk as vendor training reuse or network egress from the corporate environment. Not one names personal-account paste as the dominant exfiltration channel. The consensus cannot see the threat because it lives inside the employee's browser tab, not inside the infrastructure diagram. When the entire debate is about where the GPU sits, the real control surface — the endpoint and the identity — never appears.
How does a shadow-paste incident unfold?
Why local infrastructure cannot address the problem requires seeing the sequence clearly.
The 14-minute exfiltration chain
At 12:48, a claims handler received an underwriter's policy schedule. It named the insured, included a date of birth and carried a short medical disclosure. By 12:51 she had pasted the schedule into a personal ChatGPT account on her phone over mobile data. By 12:59 she had generated a plain-English summary and copied it into Outlook on her corporate laptop. The email went to the client at 13:02.
No DLP rule fired. No audit log captured the prompt. No controller register reflected that special-category data had moved through a US consumer AI service. Stanford HAI's 2025 AI Index reports that public confidence in AI companies protecting personal data slipped from 50% to 47% in twelve months, whilst AI-related incidents climbed 56.4% to 233 in 2024 [3]. The on-prem model in the server room had nothing to do with any of this.
Why the local LLM was irrelevant
The handler never logged into the on-prem chatbot. She had no reason to. It was slower than ChatGPT, demanded a VPN connection from her phone, and staff described its interface as "clunky" during the rollout. Consumer tools win on speed and convenience. When a sanctioned alternative is harder to use than the unsanctioned one, employees choose the unsanctioned one. Latency drives behaviour, and behaviour is the control surface that matters.
The real compliance failure was not architecture. It was the absence of three things: a sanctioned alternative that employees would actually use, DLP rules on the endpoint that blocked paste into non-approved domains, and identity controls that tied AI use to corporate accounts. Buying a GPU addresses none of those failures.
What 'local LLM' does NOT mean
The dominant SERP framing is intuitive and almost entirely wrong: that an on-prem or local LLM "solves" privacy because "zero data leaves your network", delivering GDPR, HIPAA and SOC 2 compliance as a side-effect of architecture [4]. Compliance is not a network property.
The claim, in its strongest form
Sites including AIMultiple, UnifiedAIHub and apxml.com assert that running the model locally eliminates cross-border data transfer, removes third-party processing exposure and satisfies major privacy regimes in one architectural move [4]. The intuition is physical and compelling: "Data on my server" feels safer than "data in someone else's cloud." It collapses a complex governance problem into a hardware decision that boards and auditors can visualise. GPU vendors, MLOps platforms and "private LLM" consultancies have strong commercial incentive to reinforce it. The claim persists because it flatters the buyer and enriches the seller.
Why the claim is wrong, three ways
First: network locality is not a control framework. The EU AI Act's Article 10(5) requires that where a controller processes special-category data, "only authorised persons have access to those personal data with appropriate confidentiality obligations" and that the data is not transmitted onward [5]. Those controls must exist whether the model runs on Azure or on a Dell tower in the basement. The regulation measures access design and authorisation, not geography.
Second: the ICO requires DPIAs, a documented lawful basis, accuracy controls and defined retention periods before any AI processes personal data [6]. A data protection impact assessment is a document the firm must produce. It does not appear automatically because the GPU is local.
Third: independent security analysis finds that smaller self-hosted models can be coaxed into complying with malicious prompts at materially higher rates than the hardened frontier APIs. Self-hosting shifts risk, it does not remove it. An under-governed on-prem stack with no red-team pipeline can be more exposed than a sanctioned cloud tenant with vendor-side abuse monitoring [2].
What network locality genuinely does not cover
The compliance obligations that on-prem architecture cannot satisfy by itself form a long list: lawful basis register, DPIA, accuracy controls, retention schedule, subject rights workflow, human oversight by competent persons under Article 26, six-month minimum log retention, and the employee pasting behaviour the on-prem model can never see. Architecture cannot substitute for governance; the firm must build, document and operate governance regardless of where the model runs.
Classification is the decision; venue is the consequence
Once data is classified, the local-vs-cloud question largely answers itself.
The four tiers
A four-tier framework makes the decision tractable. Tier 1 (Public) covers marketing collateral and published material — routes to any sanctioned LLM. Tier 2 (Internal) covers operational notes and non-client emails — routes to a sanctioned enterprise cloud LLM under a non-training contract. Tier 3 (Confidential) covers client PII, financial data and broker work product — requires the same enterprise cloud tenant plus EU or UK data residency, SSO-enforced identity and endpoint DLP. Tier 4 (Restricted-Regulated) covers special-category medical data, sealed legal matters and classified contracts. This is the only tier where isolated tenancy or air-gapped on-prem becomes a candidate. Classification assumes a sanctioned AI stack exists in the first place — see our framing on centralised AI strategy and why 47 ad-hoc subscriptions break this assumption.
The ICO's AI and Data Protection guidance requires a DPIA and lawful basis per processing purpose [6]. EU AI Act Article 10(5) constrains who may touch special-category data and forbids onward transmission [5]. NIST AI RMF MAP requires documented use case, context and oversight [8]. None of those obligations are satisfied by the classification framework itself: it gates the decision, then the firm must build the controls against whatever venue it selects.
Mapping tiers to Linthwaite's workload
At a 120-employee specialist insurance broker, roughly 90% of daily prompts sit in Tiers 2 to 3: internal correspondence drafting, client communication summaries, broker note formatting — all Confidential or below. Under 2% touch Tier 4, specifically the medical underwriting summaries that triggered special-category concern.
Linthwaite's on-prem deployment was scoped to serve the smallest slice while simultaneously failing the other 98%. Tier 2 and 3 workloads were not going through the on-prem model — they were going through personal ChatGPT accounts. The infrastructure investment had inverted its own purpose.
Deployer obligations follow you on-prem (the compliance side-by-side)
The "compliant by design" framing rests on a category error: it treats deployer obligations as a function of infrastructure rather than a function of use.
The obligations that do not care where the GPU sits
EU AI Act Article 26 requires deployers to assign human oversight to "natural persons who have the necessary competence, training and authority", to retain automatically generated logs for "a period appropriate to the intended purpose ... of at least six months", and to ensure input data is relevant and representative [7]. The ICO adds eight diligence questions covering lawful basis, transparency, accuracy and individual rights [1]. NIST AI RMF MAP and MEASURE require documented purpose, third-party risk and evaluation [8]. ISO/IEC 42001 turns those into an auditable management system regardless of where the firm deploys [9]. Every one of those obligations applies whether the model runs on Azure OpenAI or on a server in the basement. Article 26 sits inside a broader compliance stack — see our deep dive on building AI governance from day one for the full architectural map.
Cloud versus on-prem: who does the engineering
On a sanctioned cloud tenant, the data-processing agreement covers non-training, platform logging covers the six-month retention requirement, SSO covers identified-user oversight, and the vendor's ISO/IEC 42001 posture covers the procurement question. The NCSC expects providers to make "the most secure option as default" [10]. Major enterprise cloud LLM providers ship those controls as contractual or platform features.
On a self-hosted open-weight stack, every row in that compliance table becomes a bespoke engineering project the firm now owns and staffs. The DPIA still needs writing, the lawful basis still needs documenting, the log retention pipeline still needs building, and the human oversight programme still needs training. Sanctioned cloud is compliant by procurement; self-hosted is compliant by the firm's own engineering backlog.
Which four costs does the local-LLM pitch deck hide?
Local-LLM business cases tend to compare API line items against GPU capex and stop there. Four costs disappear in that framing.
Cost 1 — Utilisation reality
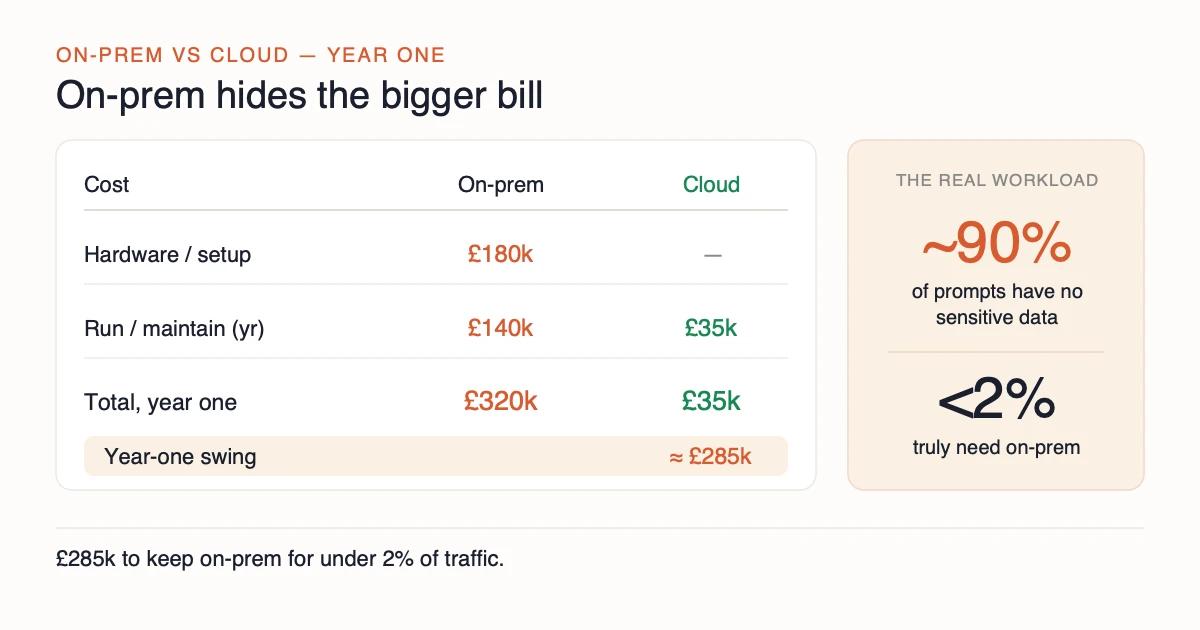
Vendor ROI models assume sustained, near-saturated GPU load against daily token volumes that only a heavily AI-integrated workflow generates. Linthwaite's measured load on its 8x A100 box was 11% average and 27% peak. Spiky, sub-saturation workloads are typical for mid-sized professional services firms. Break-even on GPU hardware at those utilisation rates stretches from under two years to most of a decade.
Cost 2 — MLOps headcount and on-call
A fully-loaded MLOps engineer in the UK runs £100–135k a year before on-call cover. Running a self-hosted model requires at minimum one person who can patch the stack, monitor drift, manage the evaluation pipeline, and respond to incidents. That headcount cost recurs every year and sits outside every GPU vendor ROI projection.
Cost 3 — Evaluation, red-team and logging debt
EU AI Act Article 26 logging requirements, ICO accuracy controls and NIST AI RMF MEASURE all require evaluation pipelines that the cloud platform largely ships and the on-prem stack does not [7, 8]. Red-teaming a self-hosted model is a fresh engineering programme. Input validation, output monitoring, incident response and model card maintenance are all standing costs that the "no API fees" narrative quietly omits.
Cost 4 — Capability decay against the frontier
Open-weight models trail the frontier on standardised reasoning benchmarks, and the gap widens on long-context reasoning and tool use over a 36-month amortisation period. Linthwaite's full alternative build was quoted at £180k capex plus £140k a year in operational costs, against £35k a year for the Azure OpenAI EU Data Boundary equivalent with zero-retention abuse monitoring. The year-one swing landed at roughly £285k for materially better capability and a cleaner audit story.
What a sanctioned cloud LLM actually buys you
A sanctioned cloud LLM is a contract and a control plane, not a vague aspiration.
The contractual surface
Microsoft's Azure OpenAI documentation states plainly that customer prompts, completions, embeddings and fine-tuning data "are NOT available to OpenAI or other Azure Direct Model providers" and "are NOT used by Azure Direct Model providers to improve their models or services" [11]. Data Zones pin processing to a customer-chosen US or EU geography. Eligible customers may apply for modified abuse monitoring, switching off the default 30-day human-review retention entirely [11]. The data-processing agreement, not a marketing page, backs those commitments.
The platform surface
SSO with Conditional Access pins every interaction to an identified corporate identity. Audit logging satisfies the six-month minimum that Article 26 imposes [7]. Content filters and customer-managed DLP cover the input-side controls the NCSC expects [2]. The vendor's ISO/IEC 42001 posture closes the procurement loop [9].
The procurement surface
The DPA covers the UK GDPR controller-processor split. The vendor publishes and versions the sub-processor list. Breach notification timelines are contractual. Residency commitments are documented. For a compliance team preparing an ICO or FCA audit pack, those artefacts are real evidence. A self-hosted stack produces equivalent artefacts only if the firm has already built the documentation programme.
When is local LLM the right answer?
There is a real, narrow lane where running the model locally is the correct call.
Genuinely restricted workloads
Three categories qualify. First: classified material where no external processor can lawfully be contracted — typically defence, security services and intelligence functions. Second: air-gapped environments where any external network path is forbidden by the applicable control framework. Third: sovereign or statutory workloads where the client contract or law forbids external processing of named data classes.
For most mid-sized firms, this lane is small. At Linthwaite, under 2% of daily prompts fell into it. When the case is genuine, an isolated tenant on a sovereign-grade private cloud is usually preferable to bare-metal on-prem: patch cadence improves, the cloud vendor supplies evaluation pipeline infrastructure, and vendor accountability exists.
What 'local' looks like when it is the right call
When a firm enters this lane, it inherits the full governance overhead: staffing, evaluation, red-team logging, incident response, model versioning, DPIA maintenance. The pattern that works is cloud as default with a narrow, explicitly scoped on-prem lane for the documented restricted slice. Classification defines where that boundary sits.
A 13-week plan to eliminate shadow paste
Phase 1 — Weeks 1-3: Classification and sanctioned tenant
Write the four-tier classification policy on one side of A4 — short enough to exist in the working memory of every manager. Provision the sanctioned cloud LLM tenant (Azure OpenAI, OpenAI Enterprise or Amazon Bedrock) under SSO with EU or UK data residency. Sign the DPA and capture the non-training commitment, residency clause and retention policy in the controller register.
Deliverable: One-page classification policy. Active SSO tenant. Signed DPA with key clauses registered.
Phase 2 — Weeks 4-8: DLP and browser controls
Deploy endpoint and browser DLP rules that block paste of Tier 2-4 content into non-sanctioned LLM domains — including chatgpt.com, claude.ai and gemini.google.com under personal accounts. Run in audit mode for the first two weeks so IT can tune the rules without blocking legitimate work, then move to enforce mode by Week 6. Run a one-hour all-hands naming the behaviour and the contracted alternative: tell employees what they have been doing without realising and show them the contracted tool that replaces it. Make switching easy, not just prohibited.
Deliverable: DLP rules in enforce mode. One-hour all-hands completed. IT incident log showing catch rate.
Phase 3 — Weeks 9-13: Governance artefacts and assurance
File DPIAs for the top three Tier 2-3 use cases as required by the ICO [6]. Configure Article 26 six-month log retention [7]. Populate the NIST AI RMF MAP register against each use case [8]. Run the internal audit pass: are the DLP rules catching attempted bypasses, and is the contracted tenant carrying the load in their place? Assemble the audit pack for regulator review.
Deliverable: Three DPIAs filed. Article 26 logging live. NIST MAP register populated. Audit pack assembled.
Across all three phases the owner question — Operations Director, ops manager promoted to AI Lead, or external hire — is itself a design decision. See our framing on why the best AI Lead hire is rarely on the market.
Anti-patterns to avoid
-
❌ Don't deploy DLP enforce-mode in Week 1 with no contracted alternative in place. Employees will route around the control via mobile data or home devices, and the DLP log will show bypass attempts rather than compliance.
-
❌ Don't write the classification policy as a 40-page document. A policy that requires twenty minutes to read will not get consulted. One side of A4, laminated, on the desk.
-
❌ Avoid tying this rollout to a wider IT transformation programme. The 13-week plan works precisely because it is standalone. Attaching it to a larger initiative delays the paste-leak fix by months and leaves the leak open.
-
❌ Avoid assuming Microsoft 365 E3 covers the controls you need. Copilot licensing and Purview DLP for AI are separate purchasing decisions with separate per-seat costs. Confirm the SKU before the rollout, not after.
Where Linthwaite landed (and the composite note)
Helena's operating state at day 90
By day ninety the on-prem rig had been retired from primary LLM duty. Microsoft 365 Copilot and Azure OpenAI were live under SSO with EU Data Boundary, and the zero-retention abuse-monitoring opt-in was pending finalisation. Endpoint DLP in enforce mode was catching four to seven attempted paste events a week, down from an estimated forty-plus before the policy landed. Three DPIAs had been filed for the top Tier 2-3 use cases, and the FCA and ICO audit pack was assembled.
Total programme spend came to about £60,000 against the alternative on-prem full build quoted at roughly £320,000 in year one.
The lesson Helena paid £160,000 to learn: data security in AI is a control-design decision, not an architecture one. Where the model runs is the smallest variable; who can touch which tier of data, on which device, under which contract, determines compliance.
Four moves close the gap. Classify the data. Sanction a cloud vendor with a non-training contract, residency and zero-retention. Put DLP on the endpoint to catch the paste before it leaves. Reserve the narrow on-prem lane only for the regulated slice that cannot be contracted to any external processor. Do those four things and the local-vs-cloud debate stops mattering, because the real exposure never lived in the box at the back of the office.
easy-audit.ai runs AI Foundation Audits for mid-sized firms working through exactly this decision: data classification, sanctioned-vendor selection, DLP control mapping, and the phased rollout plan. If you'd like to see the four-tier classification policy as a one-page template alongside the Article 26 logging checklist and the DLP rule pack, the Audit methodology page links the full set. For the buyer-side framing of these decisions, see our 50 questions decision-makers ask before AI implementation.
Composite disclosure
Linthwaite Specialty Brokers and Helena Brakespeare are composites. Both names are inventions. The firm, its size, its regulator exposure, and the sequence of events are synthesised from multiple easy-audit.ai engagements with UK specialist insurance brokers, from publicly reported ICO regulatory actions, and from anonymised conversations with compliance professionals in the sector. Every number, decision and operational pattern is real and traceable to at least one actual audit. Linthwaite is registered as a composite alongside Pavel (run-001) and Pennine (run-002) on the easy-audit.ai methodology page.
Summary
Local vs cloud LLM — the wrong security question │ ├─ Local on-prem · the seductive answer │ ├─ The claim — "data never leaves" = instant compliance │ ├─ Why it fails — governance, DPIA, logs still owed │ └─ Hidden cost — GPU capex + MLOps + capability decay │ ├─ Sanctioned cloud · the real control │ ├─ Contract — non-training DPA, EU/UK residency, SSO │ └─ DLP on endpoint — blocks the actual leak: shadow paste │ └─ Decide by classification ├─ Tiers 1–3 — ~90% of prompts route to sanctioned cloud └─ On-prem lane — only Tier 4 restricted slice (<2%)
Frequently Asked Questions
Does a sanctioned cloud LLM like Azure OpenAI really not train on our prompts?
How is shadow paste different from regular cloud AI use, and why is it the bigger risk?
Do UK regulators like the ICO or FCA require on-prem AI for handling client data?
What's the realistic cost gap between a sanctioned cloud LLM and a self-hosted open-weight stack?
Where does an on-prem LLM still make sense after this analysis?
How do I prevent prompt injection, data poisoning, and adversarial attacks on AI systems we deploy?
Where is data processed and stored when we use a hosted AI model, and does it comply with GDPR, HIPAA, and SOC 2?
Sources
- 1.Generative AI: eight questions developers and users need to ask — Information Commissioner's Office (ICO) · 2023
- 2.AI and Cyber Security: What You Need to Know — National Cyber Security Centre (NCSC) · 2024
- 3.AI Index Report 2025 — Chapter 3: Responsible AI — Stanford Institute for Human-Centered AI (HAI) · 2025
- 4.Cloud LLM vs Local LLMs: Examples and Benefits (representative SERP claim) — AIMultiple · 2025
- 5.EU AI Act, Article 10 — Data and Data Governance — Official Journal of the European Union (mirror: artificialintelligenceact.eu) · 2024
- 6.Guidance on AI and Data Protection — Information Commissioner's Office (ICO) · 2023
- 7.EU AI Act, Article 26 — Obligations of Deployers of High-Risk AI Systems — Official Journal of the European Union (mirror: artificialintelligenceact.eu) · 2024
- 8.AI Risk Management Framework 1.0 — MAP Function — NIST (AIRC mirror) · 2023
- 9.ISO/IEC 42001:2023 — Information Technology, Artificial Intelligence, Management System — International Organization for Standardization (ISO) · 2023
- 10.Guidelines for Secure AI System Development — National Cyber Security Centre (NCSC) with partners · 2023
- 11.Azure OpenAI Data, Privacy and Security — Microsoft Learn · 2025
Want this run on your business?
AI Foundation Audit — a structured assessment of your AI footprint: integration risks, governance gaps, ROI opportunities. Delivered as a comprehensive report you can act on.
You receive your Executive Report and Implementation Brief — tailored to your business and delivered immediately.